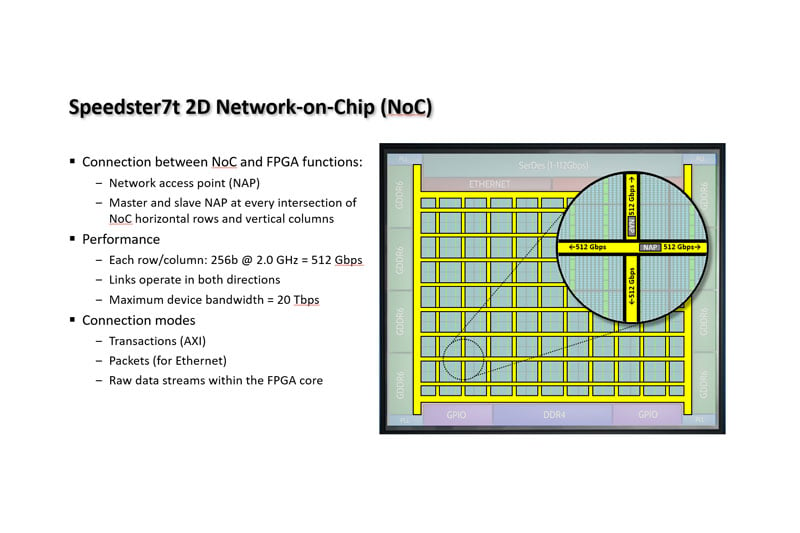
Introduction to BittWare’s Loopback App Note and Example for Network Packet Processing
White Paper Introduction to BittWare’s Loopback App Note and Example Overview BittWare’s Loopback example demonstrates several things: How to fully use the Xilinx CMAC in