大多數FPGA程式師認為,高級工具總是發出更大的比特流,作為提高生產力的“成本”。但這總是正確的嗎?在本文中,我們展示了一個真實的例子,其中我們使用傳統的RTL / Verilog工具創建了一個通用的網路功能RSS,然後在同一硬體上使用高級合成(HLS)。我們的發現令人驚訝:HLS方法實際上使用了更少的FPGA門和記憶體。這是有原因的。請繼續閱讀以瞭解詳細資訊。
用於FPGA開發的HLS方法僅抽象出可以在C / C++環境中輕鬆表達的應用程式部分。HLS工具流程基本上可用於任何BittWare開發板,方法是使用Vivado(Xilinx)或Intel(Quartus)工具。
若要成功使用 HLS,請務必識別應用程式中適合的部分。指南包括:
HLS目前的局限性顯然是其範圍僅限於IP塊。應用程式團隊仍然需要其他元件的RTL,儘管利用BittWare的SmartNIC Shell之類的東西來製作RTL部分,使用者可能能夠完全在HLS中定義他們獨特的應用程式。還應該注意的是,對於最簡單的代碼或主要由預優化元件組成的大型設計,HLS 是一個糟糕的選擇。
什麼是 RSS?RSS代表“接收器側縮放”。它是一種散列演算法,可在多個 CPU 之間有效地分配網路數據包。RSS 是現代乙太網卡上的一項功能,通常實現微軟定義的特定 Toeplitz 哈希。
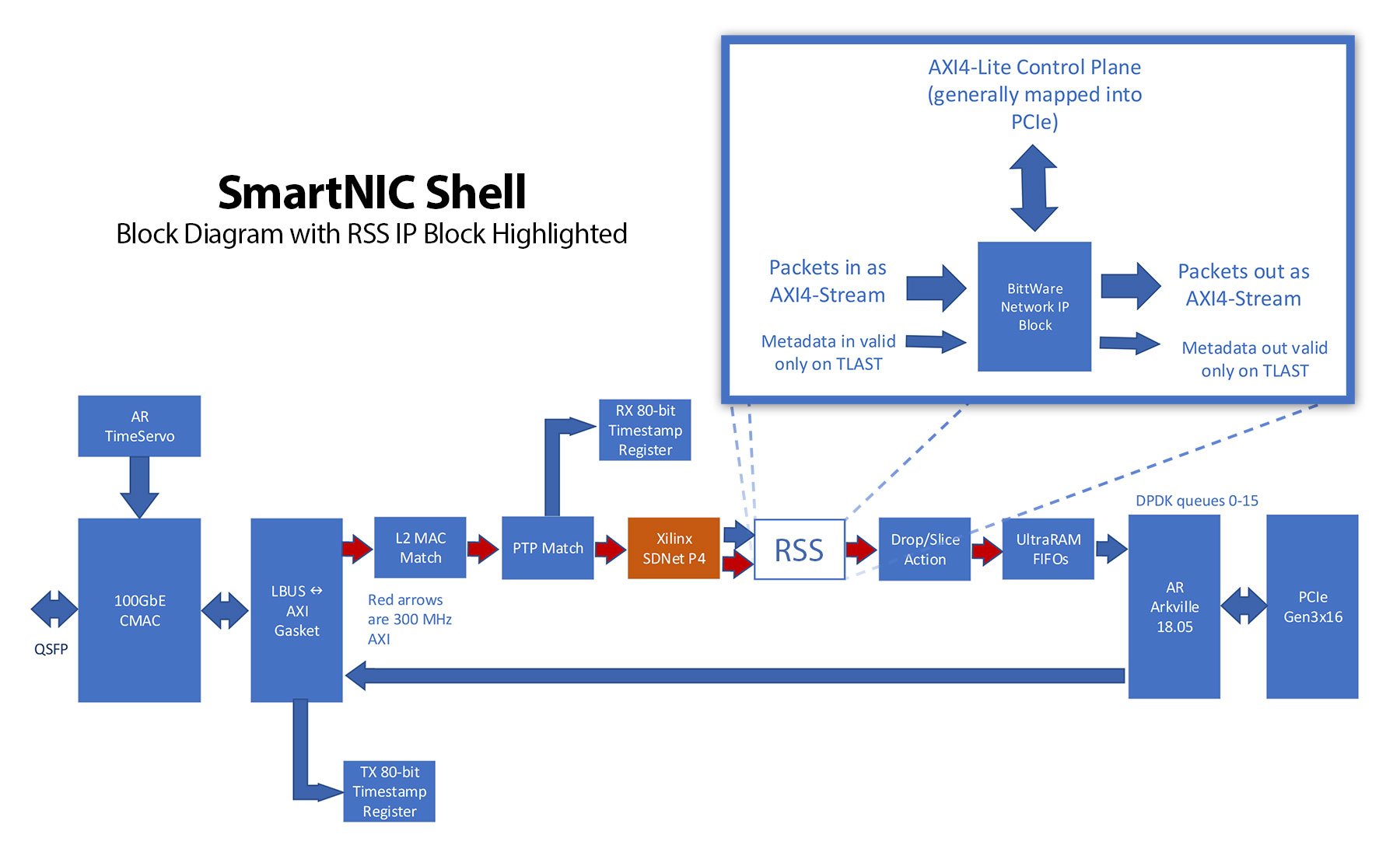
託管我們的RSS應用程式的環境是BittWare的SmartNIC Shell。SmartNIC Shell 旨在讓用戶在構建基於 FPGA 的網路應用時搶佔先機。它為使用者提供了基於 FPGA 的優化 100G 乙太網流水線,包括用於主機交互的 DPDK。使用者需要做的就是將其應用程式作為IP塊放入。
在這種情況下,BittWare也是使用者,它為我們的應用程式創建了RSS的FPGA實現。使用傳統RTL方法創建RSS的團隊和HLS團隊都能夠使用SmartNIC Shell作為他們的FPGA乙太網框架,並專注於RSS應用程式本身。
我們基於 FPGA 的 RSS 實現專門基於 DPDK 原始程式碼樹中的 C 代碼,該代碼的測試功能也在樹中可用。我們的 RSS 應用程式還使用 64 個條目的間接尋址表,而不是更常見的 128 個條目表。對於本HLS研究來說,重要的是,我們正在進入FPGA的功能是從C語言中定義的。這符合我們 HLS 成功的首要標準——C 或 C++ 中的定義。
RSS 函數的目標是在 CPU 之間分配數據包,將相關的數據包流保持在一起。不同的 Toeplitz 鍵集提供不同的分佈模式。但是,無論金鑰集如何,我們的 RSS 函數都使用每個數據包的源和目標 IP 位址以及源和目標埠作為輸入。這四個元件組合在一起稱為 4 元組。
請注意,對於我們的 RSS 應用程式,我們假設 4 元組已經被解析並添加到數據包的元數據中。另一個智慧網卡外殼模組處理此數據包分類功能。我們稱該模組為“解析器”,並將成為單獨的BittWare白皮書的主題。
我們的 RSS 實現目前接受 96 位字段進行分類,足以滿足 IPv4 源 / 目標和埠的 4 元組。解析器為數據包中不可用的欄位提供零;如果數據包不包含任何IP有效負載,則完整的96位元組字段為零。
許多 RSS 實現使用 5 元組而不是 4 元組。這樣做需要額外的8位來容納協議號。RSS 的 HLS 使用者可以通過微小的原始程式碼更改輕鬆適應這種更改。這種從 4 元組快速適應到 5 元組的能力是 HLS 成功的第二個標準的範例 - 多輪實施的要求。
傳統上,開發在FPGA內部運行的IP使用最初為ASIC開發而創建的語言。關於如何稱呼這些語言還沒有達成共識。有時人們使用“RTL”,它代表寄存器轉移語言。其他人使用「HDL」,它代表硬體定義語言。兩個最受歡迎的HDL是VHDL和SystemVerilog。在內部,BittWare同時使用兩者,但我們的大型專案使用SystemVerilog及其完整的驗證功能集。
驗證是FPGA設計過程的重要組成部分,也是ASIC設計的關鍵部分。ASIC行業成本的上升推動了對高級驗證語言和技術的需求,以確保首次通過晶元的成功。這種需求促使Verilog語言整合了HVL(高級驗證語言)的功能,最終合併到當前的SystemVerilog IEEE 1800標準中。現代ASIC驗證也已轉向通用驗證方法(UVM),該方法提供了一種構建測試平臺的標準方法。
FPGA 開發的不同經濟性以及在實驗室中立即測試設計的能力減緩了 FPGA 開發人員採用 UVM 的速度。然而,高密度FPGA日益複雜,促使許多團隊採用與ASIC設計流程相同的驗證方法。在BittWare,我們有一個流暢的FPGA驗證方法。我們經常使用基於SystemVerilog或VHDL功能的簡單測試平臺,這些功能在廉價或免費的模擬器中可用。但是,在適當的時候,我們會基於SystemVerilog和UVM的完整功能集構建現代測試平臺。
HLS或高級綜合是比HDL在更高抽象級別上運行的語言的名稱。在實踐中,HLS通常是指C或C++的專用版本。但是,還有其他HLS語言。例如,BittWare分發的一些第三方IP是用BlueSpec編寫的。所有這些HLS工具都傾向於提供一種簡單的按鈕方式,可以在模組級別生成測試平臺。在系統級別仍然需要UVM。
最後,在當今的最高級別是OpenCL。它是一種為 GPU 晶片開發的並行程式設計語言,並重新用於 FPGA 世界。如今,OpenCL 的應用程式幾乎完全是 HPC 或高性能計算,用於實現運行速度比基於 Intel 的伺服器更快的計算演算法。
儘管使用 HLS 提供了類似軟體的工具流,但開發人員仍然必須學習以硬體為中心的概念,例如流水線和反覆運算間隔,他們在為傳統處理器編寫 C 代碼時可能沒有接觸到這些概念。
HLS代碼主要用於開發嵌入式設計的IP元件,通常是流水線。我們的RSS應用程式也不例外。對於 RSS,最低性能要求是每個 512 位輸入字的處理速度足夠快,以跟上飽和的 100 Gb/s 網路介面。這相當於每個時鐘週期以300MHz的頻率處理一個新單詞。這個頻率具有挑戰性,因為即使是最快的FPGA也運行在不超過400MHz的頻率下。顯然,我們必須在每個時鐘處理一個新詞。
這引入了反覆運算間隔 (II) 的概念,它是指管道中給定邏輯片段完成所需的時鐘週期數。對於 RSS 模組,我們需要每個時鐘都有一個結果,即 1 的 II。因此,我們需要瞭解如何編寫避免違反此要求的代碼。
高II的原因包括:
代碼的主體迴圈遍歷所需的輸入元組字數,從而創建新的哈希。對於此處的示例,我們使用 3 個單詞的輸入元組作為 96 位的哈希值。
int input_len = 3; /* * The hash calculation is calculated per input tuple word. */ int32_t ret = 0; int j, i; for (j = 0; j < input_len; j++) { for (i = 0; i < 32; i++) { if (tuple_in_i[j] & (l << (32 - i ))) { ret ^= rte_cpu_to_be_32(((const uint32_t *)rss_key) [j]) << i | (uint32_t) ((uint64_t) (rte_cpu_to_be_32 (((const uint32_t *)rss_key) [j + 1])) >> (32 - i)); } } } return ret;
此代碼實現了 RSS 計算的核心。它與從 DPDK 原始程式碼樹中提取的原始檔保持不變。因此,在這個RSS塊的情況下,所有的移植工作都是定義塊的AXI介面,並將編譯指示語句添加到像II這樣的定義中。
如果輸入長度為常數,FPGA可以完全展開兩個迴圈以創建完全流水線的代碼。
要將IP元件整合到智慧NIC幀工作中,需要定義介面和控制平面,以及讀取和寫入外部介面的任何邏輯。智慧網卡框架使用 AXI 介面協定在元件之間進行通信。
定義 AXI 介面和添加雜註語句會導致代碼行過多,無法在此處的圖中顯示。完整的原始程式碼檔可從BittWare獲得。
由於 Xilinx 編譯器的常量採用英特爾位元組順序(小端序),但網路協定使用網路位元組順序(大端序),因此存在位元組序挑戰。這不會影響性能或資源使用,但要求任何輸入數據在 HLS 中處理之前更改其位元組序。
我們有兩個FPGA RSS實現的原因是因為我們的初始版本是用Verilog編寫的。這是在我們正在評估的假設下發生的:原生FPGA編碼總是導致最小的資源使用。然而,一位BittWare工程師對這一決定提出了質疑,並在HLS中重新實現了RSS來測試這種方法。他是對的,BittWare現在已經用HLS代碼替換了SmartNIC Shell中的RSS模組和解析器模組。
這兩種實現之間最大的區別是Verilog/RTL版本使用FIFO,而HLS C++版本不使用。我們驚訝地發現,遷移到 HLS 後,資源使用率實際上下降了 — 這在所有情況下都是我們意想不到的。
節省的時間呢?粗略地說,我們看到原生 RTL 版本的時程表是一個月,而 HLS 代碼在一周內完成。
本示例使用 Xilinx HLS。然而,使用高級語言的一個關鍵優勢是它們能夠在一定程度上抽象不同技術架構之間的潛在差異。英特爾還有一個等效的編譯器,該編譯器還可以編譯C++以門控 RTL 代碼。
為了使用英特爾 i++ 編譯器編譯相同的代碼,需要對數據類型進行一些細微的更改,並對#pragmas進行更改。英特爾和賽靈思之間最大的區別在於英特爾使用Avalon流介面,Xilinx使用AXI。這將需要一個簡單的填充程式介面才能從一個轉換為另一個。
一旦功能得到驗證,調用協同模擬環境進行週期精確的RTL仿真是一項微不足道的任務。Vivado-HLS自動生成一個RTL測試平臺,該測試平臺由原始C++代碼生成的向量驅動。使用者需要的唯一修改是處理其設計中的任何無限迴圈或阻塞介面。RSS 模組設計為作為韌體管道的一部分無限期運行。因此,類比將永遠不會完成,並且協同類比將掛起。為了避免這種情況,我們將 RSS 代碼的 「while (1)」 主迴圈更改為固定長度,長度足以消耗來自測試平臺的所有輸入,並且足夠長以生成所需的所有輸出。
協同模擬提供了額外的信心,即 RTL 是由工具和模組的時序特性正確生成的,符合原始設計參數。
協同模擬流程也可作為英特爾 HLS 工具堆疊的一部分提供。
HLS 工具流需要對所使用的介面協定具有內置的感知能力。BittWare的IP塊通常使用高級可擴展介面(AXI)進行通信。具體來說,AXI4-Stream 用於傳遞數據包數據,AXI4-Lite 作為控制平面。
對於100 GbE,BittWare使用512位寬的AXI4-Stream介面,時鐘頻率為300 MHz。與每個數據包關聯的元數據遵循其自己的總線,當斷言數據包數據的 TLAST 信號時,該總線在數據包末尾有效。數據包元數據在塊之間和版本之間演變。它通常包括以下資訊:
RSS 塊控制平面包括:
SmartNIC Shell框架的示例實現的SmartNIC Shell框圖。在這裡,RSS 塊被替換為 HLS 實現。
當今的高級 FPGA 開發工具旨在縮短上市時間並減少對硬體工程師的依賴。但是,使用這些工具總是會降低應用程式性能(無論是速度還是矽資源)的假設是錯誤的。
我們發現使用HLS為BittWare的SmartNIC Shell開發IP塊將開發時間從大約一個月縮短到一周。我們還發現它實際上使用更少的門來實現。
RSS塊的原始程式碼可供XUP-P3R板擁有者和SmartNIC Shell使用者使用。它很好地說明瞭如何在 HLS 代碼中使用 AXI 介面。聯繫BittWare代表以瞭解更多資訊。
除了原生開發工具外,HLS還可用於所有BittWare FPGA板。我們還提供一系列支援 OpenCL 開發的電路板 — 按兩下此處瞭解更多資訊。
瞭解有關這些參考設計的更多資訊
有關我們如何通過PCIe實現100 Gb/s的詳細資訊
返回資源