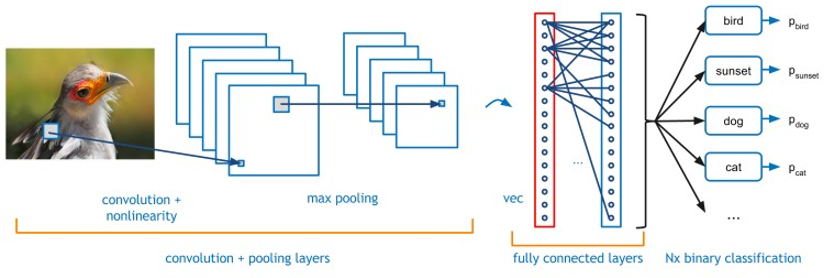
內積層具有 n 到 n 的映射,每次乘加都需要唯一的係數。內部產品層通常需要比卷積層少得多的計算,因此需要較少的邏輯並行化。在這種情況下,將內部產品層移動到主機CPU上是有意義的,而FPGA則專注於卷積。
FPGA 邏輯領域
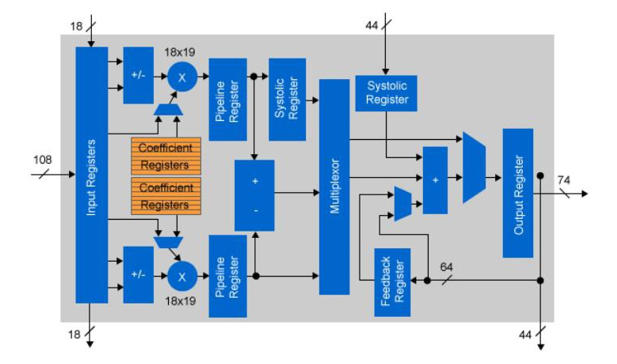
FPGA 元件有兩個 處理 區域:DSP 和 ALU 邏輯。DSP 邏輯是用於乘法或乘法加法運算子的專用邏輯。這是因為使用 ALU 邏輯進行浮點大(18×18 位)乘法的成本很高。鑒於DSP運算中乘法的通用性,FPGA供應商為此提供了專用邏輯。英特爾更進一步,允許重新配置 DSP 邏輯以執行浮點操作。為了提高CNN處理的性能,有必要增加FPGA中實現的乘法次數。一種方法是降低位精度。
空標題
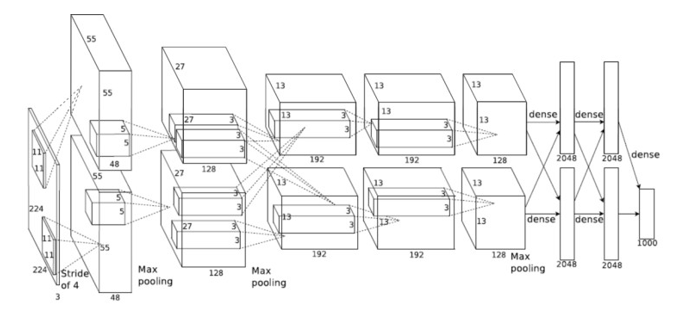
ImageNet 圖層
乘法加法 (M)
卷積 (11×11)
130
捲積 (5×5)
322
卷積 (3×3) 1
149
卷積 (3×3) 2
112
卷積 (3×3) 3
75
內積 0
37
內積 1
17
內積 2
4
表1:ImageNet層計算要求
位精度
大多數CNN實現使用浮點精度進行不同的層計算。對於 CPU 或 GPGPU 實現,這不是問題,因為浮點 IP 是晶片架構的固定部分。對於 FPGA,邏輯元件不是固定的。英特爾的Arria 10和Stratix 10設備具有嵌入式浮動DSP模組,也可以用作定點乘法。實際上,每個DSP元件都可以用作兩個獨立的18×19位乘法。通過使用18位固定邏輯執行卷積,與單精度浮點數相比,可用運算子的數量增加了一倍。