
PROVA-C 100G 網路基礎設施測試應用和設備
運行 GENEM-C 軟體的 PROVA-C 設備 運行 GENEM-C 100G 網路測試應用程式 4× 基於 BittWare 構建的 100G 1U 設備 基於 BittWare 構建 PROVA-C







運行 GENEM-C 軟體的 PROVA-C 設備 運行 GENEM-C 100G 網路測試應用程式 4× 基於 BittWare 構建的 100G 1U 設備 基於 BittWare 構建 PROVA-C

BittWare 合作夥伴 IP 查詢處理單元 (QPU) 構建 FPGA 驅動的加速器,以 PCIe Gen4 的速度查詢、分析或重新格式化存儲或流數據!艾迪康的查詢
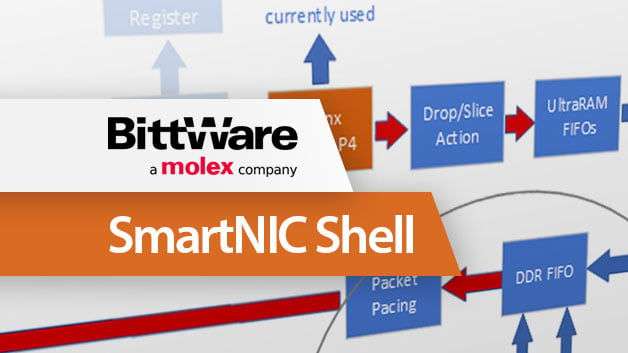
白皮書介紹BittWare的SmartNIC Shell用於網路數據包處理概述SmartNIC Shell是一個完整的工作NIC,在BittWare上實現
PCIe FPGA 卡 S7t-VG6 VectorPath Accelerator Card Achronix Speedster7t FPGA 板,帶 GDDR6 和 QSFP-DD 概述 S7t-VG6 VectorPath 加速器卡提供 7nm Achronix