
ウェビナー次世代インテルAgilex FPGAによるHPC
BittWare オンデマンド・ウェビナー 次世代インテル®Agilex™FPGAによるハイパフォーマンス・コンピューティング


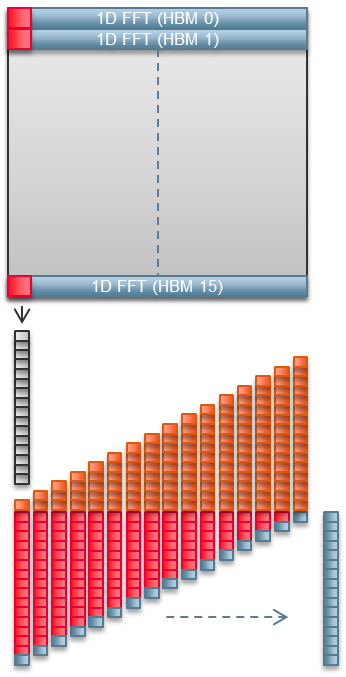
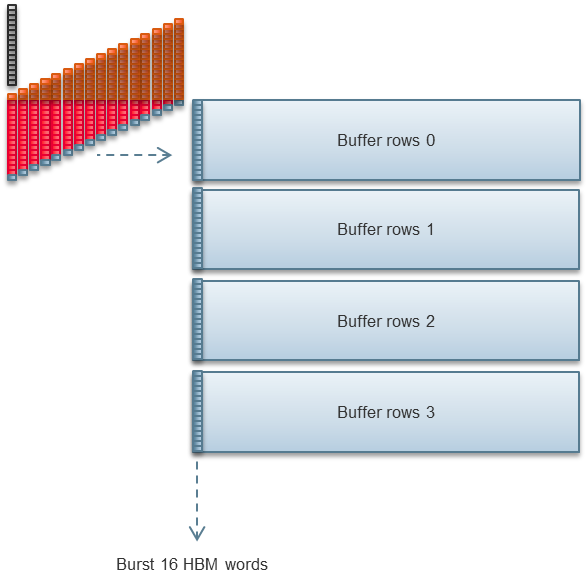
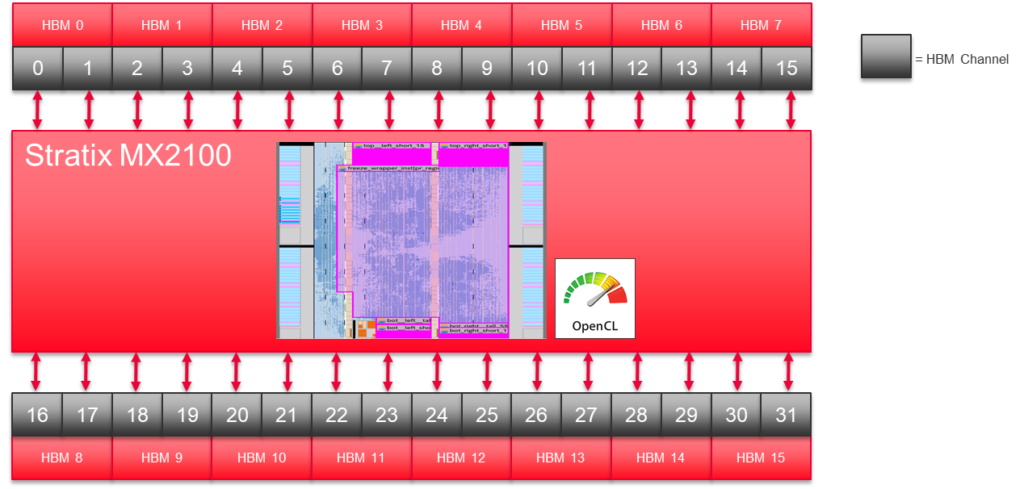 Stratix 10 MXには32個の擬似HBM2メモリチャンネルがあります。私たちの2D FFTの実装では、その半分のチャンネルを使用しています。
Stratix 10 MXには32個の擬似HBM2メモリチャンネルがあります。私たちの2D FFTの実装では、その半分のチャンネルを使用しています。
BittWare オンデマンド・ウェビナー 次世代インテル®Agilex™FPGAによるハイパフォーマンス・コンピューティング

BittWare パートナーIP NVMeブリッジ・プラットフォーム NVMeインターセプト AXI-Stream サンドボックスIP 計算機型ストレージ・デバイス(CSD)は、ストレージ・エンドポイントに計算機型ストレージ機能(CSF)を提供することができます。
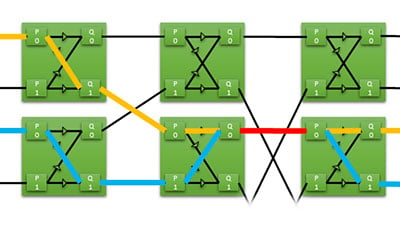
oneAPIにおけるFPGAリソースの効率的な共有 FPGAのリソース共有を解決するバタフライクロスバースイッチの構築 リソースの共有問題 FPGAカードは通常

インテル® oneAPI™ 高レベル FPGA 開発メニュー oneAPI アクセラレーター・カードの評価 ASP 詳細情報 お問い合わせ/購入先 oneAPI はあなたに適していますか?すでにご存知かもしれませんが